CPU 캐시
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
CPU 캐시는 CPU와 메인 메모리 간의 속도 차이를 해결하기 위해 사용되는 소형의 고속 메모리이다. 초기에는 가상 메모리 기술과 관련되어 발전했으며, 1980년대 이후 프로세서와 메모리 간의 성능 격차가 커지면서 중요성이 더욱 증대되었다. CPU 캐시는 L1, L2, L3, L4와 같은 여러 레벨로 구성되며, 각 레벨은 크기, 속도, 연관성 등에서 차이를 보인다. 캐시는 데이터 저장 구조, 라인 교체 방식, 데이터 갱신 방식을 통해 작동하며, 캐시 일관성 유지를 위한 다양한 기술이 사용된다. 캐시의 성능은 캐시 적중률과 미스율에 의해 결정되며, CPU 스톨, 연관성 등의 요소가 성능에 영향을 미친다. 또한, 소프트웨어는 캐시의 존재를 인식하여 성능을 최적화할 수 있다.
더 읽어볼만한 페이지
- 캐시 - 웹 캐시
웹 캐시는 웹 서버와 클라이언트 사이에서 웹 요청 응답을 저장하고 재사용하여 웹 페이지 로딩 속도를 개선하는 기술로, HTTP 프로토콜을 통해 제어되며, 디지털 밀레니엄 저작권법과 한국의 인터넷 환경에서 중요한 역할을 한다. - 캐시 - HTTP ETag
HTTP ETag는 웹 서버가 리소스의 특정 버전을 식별하기 위해 사용하는 HTTP 응답 헤더 필드로, 클라이언트는 이를 캐시하여 서버에게 리소스 변경 여부를 확인, 불필요한 데이터 전송을 줄이고 캐시 효율성을 향상시킬 수 있지만, 강력한 ETag와 약한 ETag로 구분되며 사용자 추적에 악용될 수 있다. - 중앙 처리 장치 - 마이크로컨트롤러
마이크로컨트롤러는 프로세서, 메모리, 입출력 기능을 단일 칩에 통합하여 임베디드 시스템의 핵심이 되는 부품으로, 프로그램 내장 방식을 통해 소프트웨어만으로 제어 기능 변경이 가능하며, 현재는 32비트 ARM, MIPS 아키텍처 기반 제품이 주를 이루고, 저전력 소모, 소형화, 다양한 기능 통합을 특징으로 다양한 분야에서 활용된다. - 중앙 처리 장치 - NX 비트
NX 비트는 하드웨어 기반 보안 기능으로, 메모리 페이지의 실행 권한을 제어하여 특정 영역에서 코드 실행을 막아 버퍼 오버플로 공격과 같은 보안 위협을 줄이는 데 사용되며, AMD에서 처음 도입 후 다양한 프로세서와 운영체제에서 DEP 등의 이름으로 구현되었다. - 컴퓨터 메모리 - 플래시 메모리
플래시 메모리는 전기적으로 데이터의 쓰기 및 삭제가 가능한 비휘발성 메모리 기술로, 마스오카 후지오 박사가 발명하여 카메라 플래시와 유사한 소거 방식으로 인해 명명되었으며, NOR형과 NAND형으로 나뉘어 각기 다른 분야에 적용된다. - 컴퓨터 메모리 - 메모리 계층 구조
메모리 계층 구조는 CPU 데이터 접근 속도 향상을 위해 레지스터, 캐시, RAM, 보조 기억 장치 등으로 구성되며, 속도, 용량, 비용이 다른 계층들을 통해 효율적인 메모리 관리를 가능하게 한다.
| CPU 캐시 | |
|---|---|
| 개요 | |
| 종류 | 하드웨어 캐시 |
| 사용 위치 | 중앙 처리 장치 |
| 작동 방식 | |
| 작동 원리 | 캐시는 주기억장치에서 자주 사용되는 데이터의 복사본을 저장하여, CPU가 주기억장치보다 훨씬 빠르게 접근할 수 있도록 함. CPU가 데이터에 접근할 때, 먼저 캐시를 확인하고, 데이터가 캐시에 있으면 (캐시 히트) 즉시 데이터를 사용. 데이터가 캐시에 없으면 (캐시 미스) 주기억장치에서 데이터를 가져와 캐시에 저장한 후 CPU에 제공. |
| 캐시 라인 | 캐시는 데이터를 블록 단위로 저장하며, 이 블록을 캐시 라인이라고 함. 캐시 라인은 일반적으로 64바이트 크기임. |
| 캐시 구조 | |
| 캐시 레벨 | L1 캐시: CPU 코어에 내장되어 있으며, 가장 빠르고 작은 캐시. 명령어 캐시와 데이터 캐시로 분리되어 있는 경우가 많음. L2 캐시: L1 캐시보다 크고 느리며, CPU 코어에 내장되어 있거나 CPU와 동일한 칩에 위치함. L3 캐시: L2 캐시보다 크고 느리며, 여러 CPU 코어가 공유하는 캐시. |
| 캐시 연결 방식 | 직접 매핑 캐시: 주기억장치의 각 블록이 캐시의 특정 위치에만 매핑될 수 있음. 간단하지만 충돌이 자주 발생할 수 있음. 완전 연관 캐시: 주기억장치의 각 블록이 캐시의 어느 위치에나 매핑될 수 있음. 유연하지만 검색 속도가 느림. 집합 연관 캐시: 직접 매핑과 완전 연관의 절충형. 캐시를 여러 집합으로 나누고, 각 집합 내에서는 완전 연관 방식을 사용. |
| 캐시 쓰기 정책 | 쓰기 통과 (Write-through): 데이터를 캐시와 주기억장치에 동시에 기록. 항상 최신 데이터를 유지하지만 쓰기 속도가 느림. 쓰기 백 (Write-back): 데이터를 캐시에만 기록하고, 나중에 주기억장치에 기록. 쓰기 속도가 빠르지만 데이터 손실 위험이 있음. |
| 성능 | |
| 캐시 히트율 | CPU가 캐시에서 데이터를 찾는 비율. 캐시 히트율이 높을수록 성능이 향상됨. |
| 캐시 미스율 | CPU가 캐시에서 데이터를 찾지 못하는 비율. 캐시 미스율이 낮을수록 성능이 향상됨. |
| 활용 | |
| 용도 | CPU의 데이터 접근 속도를 향상시켜 전체적인 시스템 성능을 향상시키는 데 사용됨. |
| 활용 분야 | 컴퓨터 스마트폰 서버 게임 콘솔 |
| 보안 | |
| 캐시 기반 측면 채널 공격 | CPU 캐시의 동작 특성을 이용하여 시스템의 민감한 정보를 유출하는 공격. |
2. 역사
CPU 캐시의 초기 역사는 가상 메모리의 발명 및 사용과 밀접하게 관련되어 있다.[3] 초기에는 메모리 접근 속도가 레지스터 접근 속도보다 약간 느렸다. 그러나 1980년대 이후[60] 프로세서와 메모리 간의 성능 격차가 커지면서, 메모리가 성능 병목 현상이 되었다. 이에 따라 많은 저속 메모리를 사용하면서 소형 고속 캐시 메모리를 도입하여 성능 격차를 완화하는 방식이 채택되었다.[60]
1960년대 초창기 메인프레임 컴퓨터는 복잡한 물리적 메모리 계층 구조를 사용했으며, 프로세서 접근 전에 가장 빠른 메모리로 데이터와 명령어를 가져오기 위해 캐싱이 사용되었다. 캐시 크기를 최적화하기 위한 연구가 진행되었으며, 최적의 값은 사용된 프로그래밍 언어에 따라 크게 달라졌다.
캐시 메모리는 재사용 데이터의 캐싱을 통해 실효 데이터 대역폭을 증가시킨다는 의의를 가진다. 예를 들어, 2.0 GHz로 동작하는 Haswell CPU의 싱글 코어는 피크 시 128GB/s의 데이터 접근을 요구하지만,[71] 프로세서-메인 메모리 간의 레이턴시로 인해 최대 5GB/s밖에 데이터를 읽어낼 수 없다.[73] 만약 행렬을 캐시에 모두 담을 수 있다면, 더 높은 데이터 대역폭을 확보할 수 있다.
초기 캐시는 KiB 단위로 크기가 조정되었으며, 이후 MiB 단위까지 확장되었다. 2008년 4월, 인텔 코어 2 듀오는 3 MiB L2 캐시를 사용했다. 2012년 IBM zEC12는 96 KiB L1 데이터 캐시를, 2018년 인텔 아이스 레이크 기반 프로세서는 48 KiB L1 데이터 및 명령어 캐시를 갖추었다. 2020년에는 일부 인텔 아톰 CPU가 4.5 MiB 및 15 MiB 캐시 크기를 가졌다.[9][10]
2. 1. 초기 TLB 구현
최초의 TLB(Translation Lookaside Buffer)는 GE 645[61]와 IBM 360/67[62]에서 사용되었으며, 이 TLB는 연관 메모리를 사용했다.2. 2. 최초의 명령어 캐시
최초로 문서화된 명령어 캐시 사용은 CDC 6600에서 이루어졌다.[63]2. 3. 최초의 데이터 캐시
최초로 문서화된 데이터 캐시 사용은 IBM System/360 Model 85에서 이루어졌다.[64]2. 4. 68k 마이크로프로세서
68000 계열 프로세서의 캐시 메모리 발전 과정은 다음과 같다.- 68010(1982년 출시): "루프 모드"를 제공. 이는 명령어 캐시와 유사한 기능을 수행한다.
- 68020(1984년 출시): 256바이트 명령어 캐시를 탑재. 온칩 캐시 메모리를 갖춘 최초의 68k 시리즈 프로세서이다.[4]
- 68030(1987년 출시): 256바이트 데이터 캐시와 온칩 메모리 관리 장치(MMU)를 추가.
- 68040(1990년 출시): 각각 4KiB의 분리된 명령어 및 데이터 캐시를 탑재.

마더보드 NeXTcube 컴퓨터(1990년)의 모습. 이미지 하단 중앙에서 왼쪽에는 CPU Motorola 68040이 25 MHz로 작동하며, 각 4 KiB의 별도 레벨 1 캐시 2개(명령어용 1개, 데이터용 1개)를 칩에 내장하고 있다. 이 보드에는 외부 L2 캐시가 없다. - 68060(1994년 출시): 8KiB 데이터 캐시(4방향 연관), 8KiB 명령어 캐시(4방향 연관), 96바이트 FIFO 명령어 버퍼, 256항목 분기 캐시, 64항목 주소 변환 캐시 MMU 버퍼(4방향 연관)를 탑재.
2. 5. x86 마이크로프로세서
386 마이크로프로세서가 20MHz 이상의 클럭 속도에 도달하면서, 성능 향상을 위해 시스템에 소량의 빠른 캐시 메모리가 탑재되기 시작했다. 이는 주 메모리로 사용되는 DRAM의 지연 시간 때문이었다. 캐시는 더 비싸지만 훨씬 빠른 SRAM 메모리 셀로 구성되었다.[65][66] 초기 캐시는 프로세서 외부에 있었으며, 일반적으로 마더보드에 있었다.
인텔 386 프로세서의 일부 버전은 16~256KiB의 외부 캐시를 지원할 수 있었다.
486 프로세서에서는 8KiB 캐시가 CPU 다이에 직접 통합되었다. 이 캐시는 레벨 1 또는 L1 캐시라고 불렸다. 마더보드 캐시는 펜티엄 MMX 시대까지 인기를 누렸다.
x86 마이크로프로세서의 캐시 구현에서 다음 개발은 펜티엄 프로부터 시작되었으며, 이는 2차 캐시를 마이크로프로세서와 동일한 패키지에 가져왔다.
마더보드 캐시는 AMD K6-2 및 AMD K6-III 프로세서 덕분에 오랫동안 인기를 누렸으며, L3(최대 2MiB 온보드 캐시가 있는 마더보드가 생산됨)라는 세 번째 레벨 캐시로 온보드 캐시를 활용했다. 소켓 7이 쓸모없게 된 후, 마더보드 캐시는 x86 시스템에서 사라졌다.
인텔은 하스웰 마이크로아키텍처와 함께 레벨 4 온패키지 캐시를 도입했다. ''크리스탈웰''[36] 하스웰 CPU는 128MiB의 임베디드 DRAM(eDRAM)을 탑재하고 있다. 이 L4 캐시는 CPU의 L3 캐시에 대한 피해자 캐시 역할을 한다.[37]
2. 6. ARM 마이크로프로세서
애플 M1 CPU는 코어 유형에 따라 각 코어당 128KiB 또는 192KiB의 명령어 L1 캐시를 갖추고 있는데, 이는 모든 CPU 유형에서 이례적으로 큰 L1 캐시에 해당한다. 이는 지연 시간 및 단일 스레드 성능에 중요한 영향을 미친다.[8]3. 구성
캐시 메모리는 일반적으로 하위 레벨의 기억 장치보다 용량이 작고 빠른 SRAM(Static Random Access Memory)을 사용하여 구성된다.[11] 데이터 본체의 일부와 해당 주소, 플래그 등 속성 정보의 세트를 고정 용량의 메모리에 저장한다. 데이터 저장 구조, 라인 교체, 데이터 갱신 방식, 캐시 계층 등 다양한 아키텍처가 존재한다. 이전에는 CPU 칩 외부에 연결되었지만, LSI의 집적도 향상과 요구 속도의 상승에 따라 CPU 칩 내부에 통합되는 것이 일반화되었다.
CPU 캐시의 주요 구성 요소는 다음과 같다:
- #데이터 저장 구조: 데이터를 저장하는 방식.
- #라인 교체 방식 (Refill): 캐시가 꽉 찼을 때 새로운 데이터를 저장하기 위해 기존 데이터를 교체하는 방식.
- #데이터 갱신 방식 (Replacement policy): CPU가 메모리에 쓰기 작업을 할 때 캐시된 데이터를 갱신하는 방식.
- #캐시 일관성 (Cache Coherency) : 멀티프로세서 시스템에서 데이터의 일관성을 유지하는 것.
- #기타 구성 요소: 스크래치패드 메모리, 프리페치, 태그 RAM 등.
3. 1. 캐시 계층
현대 데스크톱 컴퓨터, 서버 및 산업용 CPU는 최소 3개의 독립적인 캐시 레벨(L1, L2, L3)을 가진다.마이크로 연산 캐시, 분기 목표 버퍼를 포함하는 명령어 캐시(I-cache)는 실행 가능한 명령어 페치를 가속화하는 데 사용된다. 데이터 캐시(D-cache)는 데이터 페치 및 저장을 가속화하는 데 사용되며, 일반적으로 여러 캐시 레벨(L1, L2 등)의 계층 구조로 구성된다.[25]
더 큰 캐시는 더 나은 적중률을 가지지만 대기 시간이 더 길다. 이러한 상충 관계를 해결하기 위해, 많은 컴퓨터는 여러 단계의 캐시를 사용하며, 작고 빠른 캐시는 크고 느린 캐시로 지원된다. 다단계 캐시는 일반적으로 가장 빠른 캐시인 ''레벨 1'' ('''L1''')을 먼저 확인하여 작동한다. L1 캐시에 적중하면 프로세서가 고속으로 진행된다. 더 작은 캐시에서 실패하면 외부 메모리에 접근하기 전에 다음으로 빠른 캐시인 ''레벨 2'' ('''L2''')를 확인하는 방식 등으로 진행된다.[25]
주 기억 장치와 가장 빠른 캐시 사이의 대기 시간 차이가 커짐에 따라, 일부 프로세서는 최대 세 단계의 온칩 캐시를 활용하기 시작했다. 가격에 민감한 설계는 이를 사용하여 전체 캐시 계층 구조를 온칩으로 가져왔지만, 2010년대에 들어서면서 일부 최고 성능의 설계는 큰 오프칩 캐시로 돌아갔으며, 이는 종종 eDRAM에 구현되어 네 번째 캐시 레벨로 멀티칩 모듈에 장착되었다.[25]
L3 및 L4 캐시의 이점은 애플리케이션의 접근 패턴에 따라 다르다. 다음은 L3 및 L4 캐시를 통합한 제품의 예이다.
- 알파 21164 (1995)는 1 ~ 64 MiB의 오프칩 L3 캐시를 가지고 있었다.
- AMD K6-III (1999)는 마더보드 기반 L3 캐시를 가지고 있었다.
- IBM POWER4 (2001)는 프로세서당 32 MiB의 오프칩 L3 캐시를 가지고 있었으며, 여러 프로세서 간에 공유되었다.
- 아이테니엄 2 (2003)는 6 MiB의 통합 레벨 3 (L3) 온다이 캐시를 가지고 있었다.
- 인텔의 제온 MP 제품(코드명 "Tulsa" (2006))은 두 개의 프로세서 코어 간에 공유되는 16 MiB의 온다이 L3 캐시를 특징으로 한다.
- AMD 페넘 (2007)은 2 MiB의 L3 캐시를 가지고 있다.
- AMD 페넘 II (2008)는 최대 6 MiB의 온다이 통합 L3 캐시를 가지고 있다.
- 인텔 코어 i7 (2008)은 모든 코어가 공유하는 8 MiB의 온다이 통합 L3 캐시를 가지고 있다.
- Haswell CPU (통합 인텔 아이리스 프로 그래픽스)는 L4 캐시 역할을 하는 128 MiB의 eDRAM을 가지고 있다.
멀티 코어 칩을 고려할 때, 캐시를 공유할지 아니면 각 코어별로 로컬로 사용할지 결정해야 한다. 일반적으로 L1 캐시를 공유하는 것은 바람직하지 않은데, 지연 시간이 증가하여 각 코어가 단일 코어 칩보다 훨씬 느리게 실행될 수 있기 때문이다. 그러나 메모리에 접근하기 전에 호출되는 최상위 캐시의 경우, 단일 코어가 전체 캐시를 사용할 수 있도록 하고, 서로 다른 프로세스 또는 스레드가 캐시된 데이터를 공유할 수 있도록 하여 데이터 중복을 줄이며, 활용된 캐시 일관성 프로토콜의 복잡성을 줄이는 등 여러 가지 이유로 글로벌 캐시를 갖는 것이 바람직하다.[51]
메모리에 접근하기 전에 호출되는 공유 최상위 캐시는 일반적으로 ''최상위 레벨 캐시'' (LLC)라고 한다. LLC가 여러 코어 간에 공유될 때 병렬 처리 수준을 높이기 위해 추가 기술이 사용된다.[52]
메모리 계층을 가진 캐시 메모리를 '''멀티 레벨 캐시'''(multi level caches)라고 한다. CPU와 메모리의 성능 차이 확대, 멀티 스레드 등 접근 범위 확장에 대응하기 위해 도입된다. CPU에 가까운 쪽부터 L1 캐시(레벨 1), L2 캐시 (레벨 2)라고 불리며, 2013년 시점에서는 L4 캐시까지 CPU에 내장하는 예도 존재한다. CPU에서 봤을 때 가장 먼 캐시 메모리를 LLC(Last Level Cache)라고 부르기도 한다.
3. 2. 데이터 저장 구조
캐시 메모리는 데이터를 라인(블록)이라고 부르는 묶음 단위로 관리한다(예: 인텔 펜티엄 4의 8kByte L1 캐시는 라인 크기 64Byte).[11] 데이터 접근 시 빠른 검색을 위해 데이터 저장 주소의 일부, 즉 라인 단위 주소의 하위 비트(엔트리 주소)를 사용하여 저장 위치를 제한한다.[11] 각 라인에는 라인 단위 주소의 상위 비트(프레임 주소)를 저장하고, 캐시 검색 시 검색 주소의 프레임 주소 부분과 캐시 내 저장된 검색 엔트리 주소 위치(엔트리 주소부를 디코딩하여 라인이 하나 선택됨)에 대응하는 프레임 주소를 비교하여 캐시 히트를 검출한다. 이 프레임 주소 저장 버퍼가 태그이다.[11] 여러 세트의 태그를 가지면 동일 엔트리 주소에 여러 데이터 저장이 가능하다. 이 태그 세트 수(웨이)를 연관도라고 한다. 데이터 저장 구조의 차이는 연관도의 차이이다.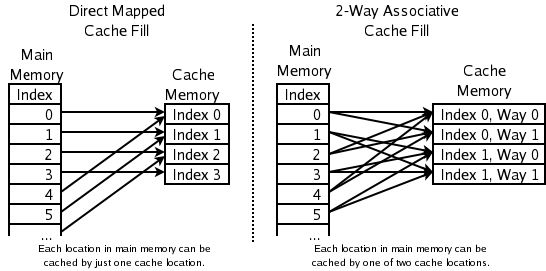
- 다이렉트 맵 방식 (Direct Mapped): 1개의 태그(연관도 1)로 구성된다.[11] 주소에 의해 배치가 유일하게 정해지므로 태그 구조가 단순하다. 그러나 동일 엔트리에 다른 프레임 주소가 전송되면 라인 교체가 반드시 발생한다. 라인 교체가 빈번해져 처리량이 떨어지는 현상(캐시 슬래싱)이 발생하기 쉽고, 히트율이 낮다.
- 세트 연관 방식 (Set Associative): 복수 태그(연관도 2 이상)로 구성된다.[11] 동일 엔트리에 다른 프레임 주소 데이터를 복수 저장할 수 있다. 연관도가 높을수록 캐시 히트율은 상승하지만, 구현이 어렵다. n개 태그로 구성된 경우 n-웨이 세트 연관 방식이라고 한다. 최근에는 CAM (연관 메모리)이 태그로 사용되어 32 등 매우 높은 연관도 구현이 가능해졌다. 다이렉트 맵 방식과 풀 연관 방식은 이 방식의 특수한 경우이다.
- 풀 연관 방식 (Fully Associative): 엔트리 주소에 의한 배분 없이 모든 라인이 검색 대상이 되는 구조이다.[11] 연관도는 라인 수와 같다. 캐시 슬래싱이 발생하기 어렵고 히트율이 가장 높지만, 구현 비용 및 복잡성 때문에 일반적으로 사용되지 않는다.
3. 3. 라인 교체 방식 (Refill)
캐시 미스 시 새로운 항목을 수용하기 위해, 캐시는 기존 항목 중 하나를 내쫓아야 한다. 내쫓을 항목을 선택하기 위해 사용하는 휴리스틱을 교체 정책이라고 한다. 모든 교체 정책의 근본적인 문제는 미래에 가장 적게 사용될 기존 캐시 항목을 예측해야 한다는 것이다. 미래를 예측하는 것은 어렵기 때문에, 사용 가능한 다양한 교체 정책 중에서 완벽한 방법은 없다. 한 가지 인기 있는 교체 정책인 최근 사용 안 함 (LRU)은 가장 최근에 접근되지 않은 항목을 교체한다.[71]라인 교체(리필)는 해당 항목의 모든 라인에 데이터가 저장되어 있는데도 동일 항목의 새로운 프레임 주소가 입력되어 캐시 미스(히트 실패)가 발생할 경우에 일어난다. 이 경우, 어떤 라인을 비우고 새로운 주소로 교체할 것인지에 대한 알고리즘에 따라 캐시 적중률이 변동한다. 대표적인 알고리즘은 다음과 같다.
- '''라운드 로빈 (Round Robin)''': 리필 대상이 되는 라인을 순서대로 교체하는 방법. 각 라인의 접근 빈도에 상관없이 순서대로 리필을 수행하므로, 적중률이 그다지 높지 않다.
- '''LRU (Least Recently Used, 최소 최근 사용)''': 가장 오래 전에 접근된 라인을 리필하는 방법. 시간적 지역성을 고려할 때, 과거에 가장 접근되지 않은 라인은 미래에도 접근될 가능성이 적다고 할 수 있다. 따라서 이 방법은 적중률이 상당히 높은 방법으로 자주 채택된다. 하지만 각 라인마다 접근 순서 이력을 가지고 접근이 있을 때마다 빈번하게 이력을 교체하므로, 복잡한 구성이 되어 접근 성능에 영향을 미치는 경우가 있다.
- '''랜덤 (Random)''': 리필 라인의 선택을 랜덤으로 수행하는 방식. 각 라인마다 리필용 기구를 가질 필요가 없어지므로 구성이 간편해진다. 적중률은 라운드 로빈보다 좋다고 여겨진다.
3. 4. 데이터 갱신 방식 (Replacement policy)
CPU가 메모리에 쓰기 작업을 할 때, 캐시된 데이터를 갱신하는 방식에는 라이트 스루(Write Through) 방식과 라이트 백(Write Back) 방식이 있다. 이 두 방식은 갱신된 데이터를 하위 레벨 메모리(예: 메인 메모리)에 반영하는 시점에 따라 구분된다.[71][72][73][74]

; 라이트 스루 방식 (Write Through Algorithm)
: CPU가 데이터를 쓸 때, CPU 캐시와 하위 레벨 메모리 모두에 동시에 데이터를 기록하는 방식이다. 이 방식은 항상 하위 레벨 메모리를 활성화시켜야 하므로, 버스 경합이나 하위 레벨 메모리의 낮은 성능에 영향을 받을 수 있다. 하지만, 구조가 단순하고 데이터 일관성을 유지하기 쉽다는 장점이 있다. 출력단에 라이트 버퍼를 추가하면, 단일 CPU 환경에서는 라이트 백 방식과 비슷한 성능을 낼 수 있다. 이러한 특징 때문에, 주로 CPU의 L1 캐시에 사용된다.
; 라이트 백 방식 (Write Back Algorithm)
: CPU가 데이터를 쓸 때, 일단 CPU 캐시에만 기록하고, 특정 조건이 만족될 때만 하위 레벨 메모리에 데이터를 쓰는 방식이다. 여기서 특정 조건이란,
:* 캐시 내 특정 라인에 새로운 데이터가 쓰여져야 하는데 해당 라인이 꽉 찼을 경우
:* 다른 장치(예: 다른 CPU 코어)가 해당 데이터에 접근하려고 할 때 데이터 일관성을 유지하기 위해서 등이 있다.
라이트 스루 방식보다 하위 레벨 메모리 버스 사용량이 적어, 여러 개의 캐시가 동일한 메모리 계층에 연결된 L2 캐시와 같이 멀티 CPU 환경에 적합하다.
라이트 백 방식에서 쓰기 실패(Write miss)가 발생했을 때, 데이터를 처리하는 방식은 두 가지가 있다.
:* '''Write allocate (Fetch on write):''' 쓰기 실패가 발생한 주소를 포함하는 라인을 캐시에 로드한 후, 쓰기 작업을 수행한다. 이 방식에서는 쓰기 실패와 읽기 실패(Read miss)가 비슷하게 동작한다.
:* '''No-write allocate (Write-no-allocate, Write around):''' 쓰기 실패가 발생한 주소의 데이터를 캐시에 로드하지 않고, 바로 하위 메모리 계층에 데이터를 쓴다. 이 방식에서는 읽기 실패 시에만 데이터가 캐시에 로드된다.
3. 5. 캐시 일관성 (Cache Coherency)
멀티프로세서 시스템에서 데이터의 일관성을 유지하는 것을 캐시 일관성(컨시스턴시)라고 한다. 여러 CPU가 동일한 메모리 영역을 참조/갱신할 때 데이터 불일치가 발생하지 않도록 보장해야 한다. 이를 위한 대표적인 알고리즘으로 스누핑 방식, 디렉토리 방식, 공유 캐시가 있다.; 스누핑 방식 (Cache Snooping)
각 캐시가 자신과 다른 CPU의 캐시 라인 갱신 상태를 파악하고 관리한다. 다른 캐시와 갱신 상태 정보를 교환하여 어떤 캐시에 최신 데이터가 있는지 확인하고, 필요에 따라 자신의 상태를 변경하거나 라인을 제거한다. 이 정보 교환은 공통 데이터 버스를 통해 이루어지므로 정보 통지와 데이터 전송 간 순서가 유지된다. 하지만 공통 버스가 없는 분산형 메모리 시스템에는 사용하기 어렵다.
- 무효화 프로토콜 (Invalidate Protocol): 한 캐시가 갱신을 수행하면, 다른 캐시의 해당 라인을 무효화한다. MESI (Illinois 프로토콜), MOSI (Berkeley 프로토콜) 등이 있다.
- 갱신형 프로토콜 (Update Protocol): 데이터 갱신 시 라이트 스루(write-through) 형식을 사용하고, 단독 접근 시 라이트 백(write-back) 형식을 사용하여 갱신 데이터를 전달한다. MEI (Firefly 프로토콜), MOES (DRAGON 프로토콜) 등이 있다.
; 디렉토리 방식 (Directory-based Protocol)
메모리 일관성을 디렉토리라는 전용 영역에서 일원적으로 관리한다. 이 영역은 각 메모리 영역에 분산되어 있어 분산 메모리형 시스템에 적합하다.
; 공유 캐시 (Shared Cache)
여러 CPU가 하나의 캐시를 참조하는 구성이다. 캐시 일관성 문제를 근본적으로 해결하지만, 캐시 구조가 복잡해지거나 성능 저하 요인이 될 수 있다.
3. 6. 기타 구성 요소
스크래치패드 메모리(SPM)는 계산, 데이터 및 기타 진행 중인 작업을 임시로 저장하는 데 사용되는 고속 내부 메모리이다.; 프리페치(Pre-fetch)
: CPU가 전용 명령 등을 통해 미리 데이터를 캐시에 가져다 놓는 동작이다.[71][72][73][74] 데이터 흐름을 어느 정도 예측할 수 있는 특정 소프트웨어 알고리즘은 미리 프리페치를 수행함으로써 실제로 데이터가 필요한 시점에서 불필요한 지연 없이 원활하게 처리할 수 있다. 예를 들어 스트리밍 처리와 같이 데이터 흐름이나 처리량이 단순하고 예측하기 쉬운 처리는 프리페치를 수행함으로써 성능을 크게 향상시킬 수 있다.
; 태그 RAM
: 컴퓨터 공학에서, ''태그 램(Tag RAM)''은 CPU 캐시에 현재 저장되어 있는 가능한 메모리 위치를 지정하는 데 사용된다.[58][59] 간단한, 직접 매핑 방식의 설계에는 빠른 SRAM을 사용할 수 있다. 더 높은 연관 캐시는 일반적으로 CAM을 사용한다.
4. 현대 프로세서의 캐시
현대 프로세서는 칩 위에 여러 캐시가 상호 작용하는 방식으로 설계되었다. 레이턴시와 히트율을 조절하는 것은 중요한 문제인데, 큰 캐시는 히트율은 높지만 레이턴시가 길다. 이러한 문제를 해결하기 위해 여러 수준의 캐시를 사용하며, 작고 빠른 캐시와 크고 느린 캐시를 함께 사용한다.[11]
일반적으로 프로세서는 가장 작은 1차 캐시(L1)부터 검사한다. 캐시가 적중하면 최고 속도로 작동하고, 실패하면 L2 캐시, 그래도 실패하면 외부 메모리를 검사한다. 메인 메모리와 캐시 사이의 레이턴시 차이가 커지면서, 일부 프로세서는 세 가지 수준의 캐시를 활용하기도 한다. 2003년 아이테니엄 2는 6 MiB 비공유 3차(L3) 캐시를, IBM 파워 4 시리즈는 256 MiB L3 캐시를, AMD 페넘 시리즈는 2MB L3 캐시를 칩 위에 장착했다.
프로세서는 주 기억 장치의 특정 위치에서 읽기/쓰기를 시도할 때, 해당 데이터가 캐시에 있는지 확인한다. 데이터가 캐시에 있다면, 느린 주 기억 장치 대신 캐시에서 읽거나 쓴다. 현대 데스크톱 컴퓨터, 서버 및 산업용 CPU는 최소 3개의 독립적인 캐시 레벨(L1, L2, L3)과 다양한 유형의 캐시를 가진다.
배치 정책은 주 메모리의 특정 항목 사본이 캐시의 어디에 위치할지를 결정한다. 배치 정책에 따라 캐시는 '완전 연관', '직접 매핑', 'N-웨이 집합 연관' 방식으로 나뉜다.[11] AMD 애슬론의 L1 데이터 캐시는 2-웨이 집합 연관 방식인데, 이는 주 메모리의 특정 위치가 L1 데이터 캐시의 두 위치 중 하나에 캐싱될 수 있음을 의미한다.
연관성 값을 선택하는 것은 트레이드 오프를 수반한다. 연관성이 높을수록 더 많은 캐시 항목을 검색해야 하므로 더 많은 전력, 칩 영역, 시간이 필요하다. 하지만 연관성이 높은 캐시는 충돌 미스가 적어 CPU가 느린 주 메모리에서 읽는 시간을 줄인다. 일반적으로 연관성을 두 배로 늘리면 캐시 크기를 두 배로 늘리는 것과 거의 동일한 히트율 상승 효과를 얻을 수 있다. 그러나 4 이상으로 연관성을 증가시키는 것은 히트율을 크게 향상시키지 않으며,[12] 다른 이유( 가상 에일리어싱 참조)로 수행된다. 일부 CPU는 저전력 상태에서 캐시의 연관성을 동적으로 줄여 전력을 절약하기도 한다.[13]
캐시 방식은 다음과 같이 분류할 수 있다.
- 직접 매핑 캐시 - 최상의 경우 시간은 좋지만 최악의 경우 예측 불가능
- 2-웨이 집합 연관 캐시
- 2-웨이 스큐드 연관 캐시[14]
- 4-웨이 집합 연관 캐시
- 8-웨이 집합 연관 캐시 (후기 구현에서 일반적인 선택)
- 12-웨이 집합 연관 캐시 (8-웨이와 유사)
- 완전 연관 캐시 - 최상의 미스율, 하지만 소수의 항목에 대해서만 실용적
최신 프로세서는 여러 개의 상호 작용하는 온칩 캐시를 가진다. 특정 캐시의 작동은 캐시 크기, 캐시 블록 크기, 세트 내 블록 수, 캐시 세트 교체 정책 및 캐시 쓰기 정책(쓰기-통과 또는 쓰기-백)에 의해 완전히 지정될 수 있다.[25]
"하위 레벨" 캐시(L1 캐시)는 블록 수, 블록 크기, 세트 내 블록 수가 적지만 접근 시간이 매우 짧다. "상위 레벨" 캐시(L2 이상)는 점진적으로 더 많은 수의 블록, 더 큰 블록 크기, 세트 내 더 많은 블록을 가지며 접근 시간이 상대적으로 길지만, 주 메모리보다 훨씬 빠르다. 캐시 항목 교체 정책은 프로세서 설계자가 구현하도록 선택한 캐시 알고리즘에 의해 결정되며, 경우에 따라 다른 종류의 작업 부하에 대해 여러 알고리즘이 제공된다.
멀티 코어 칩의 경우, 캐시 공유 여부를 결정해야 한다. 공유 캐시는 배선과 복잡성이 증가하지만, 칩당 하나의 캐시를 사용하면 필요한 공간이 크게 줄어들어 더 큰 캐시를 포함할 수 있다. L1 캐시 공유는 각 코어가 단일 코어 칩보다 훨씬 느리게 실행될 수 있기 때문에 바람직하지 않다. 그러나 최상위 캐시의 경우, 단일 코어가 전체 캐시를 사용하고, 서로 다른 프로세스나 스레드가 캐시된 데이터를 공유하여 데이터 중복을 줄이며, 캐시 일관성 프로토콜의 복잡성을 줄이는 등 여러 이유로 글로벌 캐시를 갖는 것이 바람직하다.[51] 예를 들어, 3단계 캐시를 가진 8코어 칩은 각 코어당 L1 캐시, 코어 쌍마다 중간 L2 캐시 하나, 모든 코어 간에 공유되는 L3 캐시 하나를 포함할 수 있다.
메모리에 접근하기 전에 호출되는 공유 최상위 캐시는 ''최상위 레벨 캐시''(LLC)라고 한다. LLC가 여러 코어 간에 공유될 때 병렬 처리 수준을 높이기 위해 특정 메모리 주소 범위를 지정하고 독립적으로 접근할 수 있는 여러 조각으로 나누는 등의 추가 기술이 사용된다.[52]
분리형 캐시 구조에서는 명령어와 데이터를 별도로 캐싱한다. 즉, 캐시 라인은 명령어 또는 데이터 중 하나를 캐싱하는 데 사용되며, 둘 다 캐싱할 수는 없다. 분리된 데이터 및 명령어 번역 색인 버퍼는 다양한 이점을 보여주었다.[53] 통합형 구조에서는 이러한 제약이 없으며, 캐시 라인은 명령어와 데이터를 모두 캐싱하는 데 사용될 수 있다.
다단계 캐시는 새로운 설계 결정을 도입한다. 일부 프로세서는 L1 캐시의 모든 데이터가 L2 캐시에도 존재해야 하는 ''엄격 포괄형'' 캐시를 사용하고, AMD 애슬론과 같은 다른 프로세서는 데이터가 L1과 L2 캐시 중 하나에만 존재하도록 보장되는 ''배타형'' 캐시를 사용한다. 인텔 펜티엄 II, III, 4와 같은 프로세서는 L1 캐시의 데이터가 L2 캐시에 반드시 존재해야 하는 것은 아니지만, 종종 그럴 수 있는 중간 정책을 사용한다. 이 중간 정책에 대해 보편적으로 통용되는 이름은 없으며,[54][55] "비배타형"과 "부분 포괄형"이라는 두 가지 이름이 있다.
배타형 캐시는 더 많은 데이터를 저장할 수 있다는 장점이 있다. L1에서 미스가 발생하고 L2에서 히트가 발생할 때, L2에서 히트된 캐시 라인은 L1의 라인과 교환된다. 이 교환은 L2에서 L1으로 라인을 복사하는 것보다 더 많은 작업이 필요하다.[55]
엄격 포괄형 캐시는 외부 장치나 다중 프로세서 시스템의 다른 프로세서가 프로세서에서 캐시 라인을 제거하려는 경우 L2 캐시만 확인하면 된다는 장점이 있다. 포괄성을 강제하지 않는 캐시 계층 구조에서는 L1 캐시도 확인해야 한다. 단점으로는 L1 및 L2 캐시의 연관성 간에 상관 관계가 있다는 것이다. L2 캐시에 모든 L1 캐시를 합한 것만큼 많은 웨이가 없으면 L1 캐시의 유효 연관성이 제한된다. 또한 L2 캐시에서 제거가 발생할 때마다, 해당 라인이 L1에서도 제거되어야 하므로 L1 미스율이 높아진다.[55]
포괄형 캐시의 또 다른 장점은 더 큰 캐시가 더 큰 캐시 라인을 사용할 수 있어 보조 캐시 태그의 크기를 줄일 수 있다는 것이다.[56]
K8 코어의 AMD Athlon 64 CPU의 캐시 계층 구조는 전문화와 다단계 캐싱을 모두 보여주는 예시이다.[57]

K8은 명령어 캐시, 명령 TLB, 데이터 TLB 및 데이터 캐시의 4개의 특수화된 캐시를 가지고 있다.
- 명령어 캐시: 64바이트 메모리 라인의 사본을 보관하며, 매 사이클마다 16바이트를 가져온다. 각 바이트는 10비트로 저장되며, 추가 비트는 명령어 경계를 표시한다. 패리티 보호만 있으며, ECC는 없다.
- 명령 TLB: 페이지 테이블 항목(PTE)의 사본을 보관한다. 매 사이클의 명령어 인출은 이 TLB를 통해 가상 주소를 물리 주소로 변환한다. K8은 가변 페이지 크기를 가지므로, 각 TLB는 4 KiB 페이지를 매핑하는 PTE와 4 MiB 또는 2 MiB 페이지를 매핑하는 PTE를 보관하는 섹션으로 나뉜다.
- 데이터 TLB: 동일한 항목을 보관하는 두 개의 사본을 가진다. 사이클당 두 번의 데이터 액세스로 가상 주소를 물리 주소로 변환할 수 있다.
- 데이터 캐시: 64바이트 메모리 라인의 사본을 보관한다. 8개의 뱅크(각 8 KiB의 데이터 저장)로 분할되어 있으며, 해당 데이터가 서로 다른 뱅크에 있는 한 매 사이클마다 8바이트 데이터를 두 번 가져올 수 있다.
K8은 다단계 캐시도 가지고 있다. 4 KiB만 매핑하는 PTE를 저장하는 2단계 명령 및 데이터 TLB가 있다. 명령 및 데이터 캐시와 TLB는 큰 '''통합''' L2 캐시에서 채워질 수 있다. 이 캐시는 L1 명령 및 데이터 캐시에 배타적이므로, 8바이트 라인은 L1 명령 캐시, L1 데이터 캐시 또는 L2 캐시 중 하나에만 있을 수 있다. 운영 체제는 메모리의 페이지 테이블이 업데이트될 때 TLB의 일부를 플러시하여 TLB를 일관성 있게 유지해야 한다.
K8은 예측 정보도 캐싱한다. 비교적 복잡한 분기 예측을 가지고 있으며, 분기 실행 여부 및 분기/점프 대상을 예측하는 테이블이 있다. 이 정보의 일부는 L1 명령 캐시와 통합 2차 캐시 모두에서 명령어와 연관되어 있다. K8은 2차 캐시의 명령어와 함께 예측 정보를 저장하는데, 2차 캐시 라인은 ECC 또는 패리티에 의해 보호된다. 패리티 코드가 ECC 코드보다 적은 비트를 사용하므로, 명령 캐시 라인의 여분 비트를 활용해 분기 예측 정보를 캐싱한다.
DEC 알파 21264의 store-to-load 바이패스 예측기처럼 다른 프로세서들은 다른 종류의 예측기를 가지며, 미래에는 다양한 전문화된 예측기가 등장할 가능성이 높다. 예측기는 계산 비용이 많이 드는 정보를 저장한다는 점에서 캐시와 유사하지만, 일반적으로 캐시 계층 구조의 일부로 간주되지 않는다.
K8은 명령 및 데이터 캐시의 일관성을 하드웨어적으로 유지한다. 알파 및 MIPS 계열의 프로세서와 같은 다른 프로세서들은 소프트웨어에 의존하여 명령 캐시를 일관되게 유지해 왔다.
초기 캐시 설계는 캐시 및 램의 직접적인 비용과 평균 실행 속도에 집중했다. 최근에는 에너지 효율, 내결함성 등도 고려한다.[68][69] CACTI 캐시 시뮬레이터[70] 및 SimpleScalar 명령 집합 시뮬레이터와 같은 도구들이 설계에 활용된다.
다중 포트 캐시는 한 번에 둘 이상의 요청을 처리할 수 있는 캐시이다. 일반적인 캐시는 단일 메모리 주소를 사용하지만, 다중 포트 캐시에서는 프로세서와 캐시를 통해 연결된 포트의 수(N)만큼 한 번에 N개의 주소를 요청할 수 있다. 이는 파이프라인 프로세서가 파이프라인의 여러 단계에서 메모리에 접근하거나, 서로 다른 캐시 레벨을 통해 슈퍼스칼라 프로세서의 개념을 가능하게 한다.
캐시 메모리는 재사용 데이터 캐싱을 통해 실효 데이터 대역폭을 증가시킨다. 예를 들어, 2.0 GHz Haswell CPU의 싱글 코어는 SGEMV 연산에서 피크 시 128GB/s의 데이터 접근을 요구하지만,[71] 프로세서-메인 메모리 간 레이턴시로 인해 최대 5GB/s밖에 데이터를 읽어낼 수 없다.[73] 캐시를 활용하면 더 높은 데이터 대역폭을 확보할 수 있다.
4. 1. 특수 캐시
CPU는 파이프라인의 여러 지점에서 메모리에 접근하는데, 명령어 인출, 가상 주소-물리 주소 변환, 데이터 인출 등이 있다. 이러한 각 지점에 서로 다른 물리적 캐시를 사용하여, 하나의 물리적 자원이 파이프라인의 두 지점을 처리하지 않도록 설계되었다. 따라서 파이프라인은 자연스럽게 각자의 역할에 특화된 최소 3개의 별도 캐시(명령어, 변환 색인 버퍼, 데이터)를 갖게 된다.'''희생 캐시'''는 CPU 캐시에서 교체 시 쫓겨난 블록을 보관하는 데 사용되는 캐시이다. 희생 캐시는 주 캐시와 리필 경로 사이에 위치하며 주 캐시에서 쫓겨난 데이터 블록만 보관한다. 이는 충돌 미스 수를 줄이기 위한 것으로, 노먼 주피(Norman Jouppi)가 1990년에 소개하였다.[35]
인텔의 ''크리스털웰(Crystalwell)''[36]은 하스웰 프로세서의 변종으로, 프로세서의 레벨 3 캐시에 대한 희생 캐시 역할을 하는 온 패키지 128 MiB eDRAM 레벨 4 캐시를 도입했다.[37] 스카이레이크 마이크로아키텍처에서는 레벨 4 캐시가 더 이상 희생 캐시로 작동하지 않는다.[38]
인텔 펜티엄 4 마이크로프로세서에서 찾아볼 수 있는 '''트레이스 캐시''' (실행 트레이스 캐시라고도 함)는 이미 가져와서 디코딩된 명령어의 트레이스를 저장하여 명령어 인출 대역폭을 늘리고 전력 소비를 줄이는 메커니즘이다.[39] 펜티엄 4의 트레이스 캐시는 x86 명령어를 디코딩한 결과인 마이크로 연산을 저장하며, 마이크로 연산 캐시의 기능도 제공한다.[43]
Write Coalescing Cache[40]는 AMD의 불도저 마이크로아키텍처의 L2 캐시에 포함된 특수한 캐시이다. 모듈 내의 두 L1D 캐시 모두에서 발생하는 쓰기 작업은 WCC를 거치며, 여기서 버퍼링되고 병합된다. WCC의 역할은 L2 캐시에 대한 쓰기 횟수를 줄이는 것이다.
'''마이크로 오퍼레이션 캐시'''('''μop 캐시''', '''uop 캐시''' 또는 '''UC''')[41]는 명령어 디코더 또는 명령어 캐시에서 직접 수신한 디코딩된 명령어의 마이크로 오퍼레이션을 저장하는 특수 캐시이다. 인텔은 샌디 브릿지 프로세서와 아이비 브릿지 및 하스웰과 같은 후속 마이크로아키텍처에 μop 캐시를 포함했다.[43][44] AMD는 자사의 젠 마이크로아키텍처에 μop 캐시를 구현했다.[45]
'''분기 대상 캐시''' 또는 '''분기 대상 명령어 캐시'''는 ARM 마이크로프로세서에서 사용되는 이름[47]으로, 실행된 분기의 목적지에 있는 처음 몇 개의 명령어를 저장하는 특수한 캐시이다.
'''스마트 캐시'''는 2단계 또는 3단계 캐싱 방식으로, 인텔(Intel)에서 여러 실행 코어를 위해 개발했다. 스마트 캐시는 멀티 코어 프로세서의 코어 간에 실제 캐시 메모리를 공유한다. 코어별 전용 캐시에 비해, 코어가 캐시 공간을 동일하게 필요로 하지 않을 때 전체 캐시 미스율이 감소한다.[48]
5. 가상 메모리와 주소 변환
일반적인 CPU는 가상 메모리를 사용하는데, 이는 각 프로그램에 자체적인 주소 공간을 제공하거나 모든 프로그램이 공통 가상 주소 공간에서 실행되도록 한다. 프로그램은 가상 주소 공간에서 실행되므로 실제 주소가 아닌 가상 주소를 사용하여 더 간단하게 작성할 수 있다.
가상 메모리를 사용하면 프로세서는 가상 주소를 실제 주소로 변환해야 하며, 이 변환은 메모리 관리 유닛(MMU)이 담당한다. MMU는 페이지 테이블이나 세그먼트 테이블의 매핑 정보를 담은 TLB(Translation Lookaside Buffer)를 통해 빠르게 변환을 수행할 수 있다.
초기 가상 메모리 시스템인 IBM M44/44X는 매핑 테이블 접근 전에 코어 메모리에 접근해야 했다.[28] 이는 메모리 접근 속도를 절반으로 줄였다. IBM System/360 Model 67과 GE 645는 페이지 테이블 접근을 위한 캐시로 소형 연관 메모리를 사용했다. 이들은 IBM System/360 Model 85보다 먼저 나왔으므로, 최초의 하드웨어 캐시는 데이터나 명령어 캐시가 아니라 TLB였다.
CPU 성능에는 로드 지연 시간을 줄이는 것이 중요하다. 따라서 최신 1단계 캐시는 대부분 가상 인덱싱을 사용한다. 그러나 가상 별칭 처리 비용은 캐시 크기가 커질수록 증가하므로, 대부분의 2단계 이상 캐시는 물리적으로 인덱싱된다. 과거에는 캐시 태그에 가상 주소와 실제 주소를 모두 사용했지만, 현재는 가상 태깅은 흔하지 않다.
5. 1. 주소 변환의 특징
가상 메모리를 구현하는 CPU는 메모리 관리 유닛(MMU)을 사용하여 가상 주소를 실제 주소로 변환한다. 이 변환 과정에는 다음과 같은 세 가지 주요 특징이 있다.- '''지연 시간''': 가상 주소를 실제 주소로 변환하는 데에는 시간이 걸린다. 실제 주소는 가상 주소가 사용 가능해진 후 몇 사이클이 지나야 MMU에서 사용할 수 있다.
- '''가상 에일리어싱''': 여러 개의 가상 주소가 하나의 실제 주소에 매핑될 수 있다. 프로세서는 이러한 경우에도 프로그램 순서대로 업데이트가 이루어지도록 보장해야 한다. 이를 위해 특정 시점에 실제 주소의 사본이 캐시에 하나만 존재하도록 관리한다.[28]
- '''세분성''': 가상 주소 공간은 페이지 단위로 나뉜다. 예를 들어, 4GiB 가상 주소 공간은 각각 4KiB 크기의 페이지 1,048,576개로 나눌 수 있으며, 각 페이지는 독립적으로 매핑될 수 있다.
이러한 특징들은 CPU 캐시의 설계 및 작동 방식에 영향을 미친다. 특히 가상 인덱싱과 물리 인덱싱, 가상 태깅과 물리 태깅 등의 개념은 주소 변환 방식과 관련이 있다.
5. 2. 캐시의 주소 사용 방식
CPU영어 캐시는 인덱스와 태그에 사용되는 주소의 종류에 따라 다음과 같이 네 가지로 나눌 수 있다.- '''물리적 인덱스, 물리적 태그 (PIPT)''' : 인덱스와 태그 모두에 실제 주소를 사용한다. 단순하고 별칭 문제가 없지만, 실제 주소를 먼저 조회해야 하므로 속도가 느리다. 캐시 조회 전에 TLB 미스 및 주기억장치 접근이 발생할 수 있다.[30]
- '''가상 인덱스, 가상 태그 (VIVT)''' : 인덱스와 태그 모두에 가상 주소를 사용한다. 메모리 관리 유닛(MMU)을 참조할 필요 없이 빠르게 조회할 수 있지만, 별칭 및 동음이의어 문제가 발생할 수 있다.[29]
- '''가상 인덱스, 물리적 태그 (VIPT)''' : 인덱스에는 가상 주소를, 태그에는 실제 주소를 사용한다. TLB 변환과 병렬로 캐시 라인을 조회하여 지연 시간을 줄이고, 태그에 실제 주소가 있어 동음이의어를 감지할 수 있다.
- '''물리적 인덱스, 가상 태그 (PIVT)''' : MIPS 아키텍처 R6000에서 사용되는 방식이다.[31] TLB 슬라이스에서 얻은 실제 주소로 인덱싱하고, 가상 주소로 태깅하여 잘못된 캐시 적중을 해결한다.
대부분의 최신 1단계 캐시는 가상 인덱싱을 사용하는데, 이는 MMU의 TLB 조회가 캐시 RAM에서 데이터를 가져오는 것과 병렬로 진행될 수 있게 하여 로드 지연 시간을 줄이는 데 중요하다. 그러나 가상 별칭 처리 비용은 캐시 크기가 커질수록 증가하므로, 2단계 이상의 캐시는 대부분 물리적으로 인덱싱된다.
과거에는 캐시 태그에 가상 주소와 실제 주소를 모두 사용했지만, 현재는 가상 태깅이 흔하지 않다. 대신, 가상 힌트(vHint)가 사용되기도 한다.
6. 캐시 성능
현대 프로세서는 칩 위에 다양한 캐시를 가지고 상호작용한다. 주 기억 장치에서 특정 위치의 데이터를 읽거나 쓰려고 할 때, 프로세서는 해당 데이터가 이미 캐시에 있는지 확인한다. 만약 캐시에 데이터가 있다면, 프로세서는 훨씬 느린 주 기억 장치 대신 캐시에서 데이터를 읽거나 쓴다.
많은 현대 데스크톱 컴퓨터, 서버 및 산업용 CPU는 최소 3개의 독립적인 캐시 레벨(L1, L2 및 L3)과 다양한 유형의 캐시를 가지고 있다.
- '''명령어 캐시''': 실행 가능한 명령어 페치를 가속화하는 데 사용된다.
- '''데이터 캐시''': 데이터 페치 및 저장을 가속화하는 데 사용된다. 데이터 캐시는 일반적으로 여러 캐시 레벨(L1, L2 등)의 계층 구조로 구성된다. (다단계 캐시 참조)
변환 색인 버퍼(TLB)는 실행 가능한 명령어와 데이터 모두에 대한 가상 주소를 물리 주소로 변환하는 속도를 높이는 데 사용되지만, 메모리 관리 장치(MMU)의 일부이며 CPU 캐시와 직접 관련이 없다.
캐시 미스로 인해 CPU가 데이터를 기다리는 동안 작업을 다 써버리는 현상을 스톨이라고 한다. CPU가 메인 메모리에 비해 더 빨라짐에 따라 캐시 미스에 의한 스톨은 더 많은 잠재적 계산을 대체한다. 최신 CPU는 메인 메모리에서 단일 캐시 라인을 가져오는 데 걸리는 시간 안에 수백 개의 명령을 실행할 수 있다.[71]
이러한 현상을 방지하기 위해 다양한 기술들이 사용되는데, 여기에는 캐시 미스 데이터를 기다리는 명령 뒤에 독립적인 명령을 실행하려는 CPU의 비순차적 실행이 포함된다. 많은 프로세서에서 사용되는 또 다른 기술은 동시 멀티스레딩(SMT)으로, 첫 번째 스레드가 필요한 CPU 리소스를 사용할 수 있을 때까지 기다리는 동안 다른 스레드가 CPU 코어를 사용할 수 있도록 한다.
예를 들어, 2.0 GHz로 동작하는 Haswell CPU의 싱글 코어는 SGEMV(단정밀 부동소수점의 행렬-벡터 곱 연산)에서 피크 시 128GB/s의 데이터 접근을 요구한다.[71] 그러나 프로세서와 메인 메모리 간의 지연 시간은 수백 사이클이며, 병렬 로드를 수행하더라도 최대 5GB/s밖에 데이터를 읽어낼 수 없다.[73] 즉, 메모리 병목 현상으로 인해 CPU 성능의 5% 이하밖에 끌어낼 수 없다.[74] 만약 행렬을 캐시에 모두 담을 수 있다면, 지연 시간이 더 작은 캐시 메모리에서 데이터를 공급하여 더 높은 데이터 대역폭을 확보할 수 있다.
배치 정책은 주 메모리의 특정 항목 사본이 캐시 어디에 위치할지를 결정한다. 배치 정책에 따라 다음과 같이 분류할 수 있다.
- 완전 연관 (Fully Associative): 캐시의 임의 항목을 선택하여 사본을 보관할 수 있다.
- 직접 매핑 (Direct Mapped): 주 메모리의 각 항목이 캐시의 단 하나의 위치에만 매핑될 수 있다.
- N-웨이 집합 연관 (N-way Set Associative): 주 메모리의 각 항목이 캐시의 N개 위치 중 하나에 매핑될 수 있다. 예를 들어, AMD 애슬론의 레벨-1 데이터 캐시는 2-웨이 집합 연관 방식으로, 주 메모리의 특정 위치가 레벨-1 데이터 캐시의 두 위치 중 하나에 캐싱될 수 있다.[11]
적절한 연관성 값을 선택하려면 트레이드 오프가 필요하다. 배치 정책이 메모리 위치를 매핑할 수 있는 위치가 많을수록 해당 위치가 캐시에 있는지 확인하기 위해 더 많은 캐시 항목을 검색해야 한다. 이는 더 많은 전력, 칩 영역, 시간을 소모한다. 반면, 연관성이 높을수록 충돌 미스가 줄어들어 CPU가 느린 주 메모리에서 데이터를 읽는 데 낭비하는 시간이 줄어든다.
일반적으로 연관성을 두 배로 늘리면 (예: 직접 매핑 → 2-웨이, 2-웨이 → 4-웨이) 캐시 크기를 두 배로 늘리는 것과 거의 동일한 히트율 상승 효과를 얻을 수 있다. 그러나 연관성을 4 이상으로 증가시키는 것은 히트율을 크게 향상시키지 않으며,[12] 다른 이유 (가상 에일리어싱 참조)로 수행된다.[12] 일부 CPU는 저전력 상태에서 캐시 연관성을 동적으로 줄여 전력을 절약한다.[13]
캐시 연관성은 단순하지만 상황이 좋지 않은 것부터 복잡하지만 상황이 좋은 순서로 다음과 같이 나열할 수 있다.
- 직접 매핑 캐시: 최상의 경우 시간은 좋지만 최악의 경우 예측 불가능하다.
- 2-웨이 집합 연관 캐시
- 2-웨이 스큐드 연관 캐시[14]
- 4-웨이 집합 연관 캐시
- 8-웨이 집합 연관 캐시 (후기 구현에서 일반적인 선택)
- 12-웨이 집합 연관 캐시 (8-웨이와 유사)
- 완전 연관 캐시: 최상의 미스율을 보이지만 소수의 항목에 대해서만 실용적이다.
캐시 메모리는 데이터를 라인(블록) 단위로 관리한다. (예: Intel Pentium 4의 8KB L1 캐시는 64바이트 라인 크기를 가짐). 데이터 접근 요구 시 해당 데이터가 캐시에 존재하는지, 어떤 라인에 있는지 등을 빠르게 (대부분 1사이클 처리량) 검색해야 한다. 이를 위해 데이터 저장 주소 일부 (라인 단위 주소의 하위 비트, 엔트리 주소)를 이용하여 저장 위치를 한정하여 검색 속도를 높인다.
각 라인에는 라인 단위 주소의 상위 비트 (프레임 주소)를 저장하고, 캐시 검색 시 검색 주소의 프레임 주소부와 캐시 내 저장된 검색 엔트리 주소 위치 (엔트리 주소부를 디코딩하여 라인 선택)에 대응하는 프레임 주소를 비교하여 캐시 히트를 검출한다. 이 프레임 주소 저장 버퍼가 태그이다. 여러 세트의 태그를 가지면 동일 엔트리 주소에서도 여러 데이터 저장이 가능하다. 이 태그 세트 수 (웨이)를 연관도라고 하며, 데이터 저장 구조의 차이는 연관도의 차이로 나타난다.
- 다이렉트 맵 방식 (Direct Mapped): 1개 태그로 구성 (연관도 1)된 데이터 저장 구조이다. 주소에 의해 배치가 유일하게 결정되므로 태그 구조가 단순하다. 하지만 동일 엔트리에 다른 프레임 주소가 전송되면 반드시 라인 교체가 발생한다. 라인 교체가 빈번하여 처리량이 떨어지는 캐시 슬래싱이 발생하기 쉽고 히트율이 높지 않다.
- 세트 연관 방식 (Set Associative): 복수 태그로 구성 (연관도 2 이상)된 데이터 저장 구조이다. 동일 엔트리에 다른 프레임 주소 데이터를 복수 저장할 수 있다. 연관도가 높을수록 캐시 히트율이 상승하지만 제조가 어렵기 때문에 시스템에 따라 균형 잡힌 구현이 필요하다. n개 태그로 구성된 경우 n-웨이 세트 연관 방식이라고 한다. 최근에는 CAM (연관 메모리)이 태그로 사용되어 32 등 매우 높은 연관도 구현이 가능해졌다. 다이렉트 맵 방식과 풀 연관 방식은 이 방식의 특수한 경우이다.
- 풀 연관 방식 (Fully Associative): 엔트리 주소에 의한 배분 없이 모든 라인이 검색 대상이 되는 구조이다. 연관도는 라인 수만큼 된다. 캐시 슬래싱이 일어나기 어렵고 히트율이 가장 우수하지만 구현 비용 및 복잡성 때문에 일반적으로 사용되지 않는다.
6. 1. 캐시 적중률과 미스율
캐시 성능은 캐시 적중률과 미스율에 의해 결정된다. 캐시 적중은 프로세서가 캐시에서 데이터를 찾을 때 발생하며, 캐시 미스는 캐시에서 데이터를 찾지 못할 때 발생한다.[32]프로세서가 메모리 위치를 읽거나 쓰려고 할 때, 먼저 캐시에 해당 항목이 있는지 확인한다. 캐시는 해당 주소를 포함할 수 있는 캐시 라인에서 요청된 메모리 위치의 내용을 확인하여 작동한다. 프로세서가 메모리 위치가 캐시에 있음을 발견하면, '''캐시 히트'''가 발생한 것이다. 반대로, 프로세서가 캐시에서 메모리 위치를 찾지 못하면, '''캐시 미스'''가 발생한 것이다. 캐시 히트의 경우, 프로세서는 즉시 캐시 라인에서 데이터를 읽거나 쓴다. 캐시 미스의 경우, 캐시는 새로운 항목을 할당하고 메인 메모리에서 데이터를 복사한 다음, 캐시의 내용에서 요청을 충족한다.[32]
캐시 미스는 캐시에 있는 데이터를 읽거나 쓰려는 시도가 실패하여 메인 메모리에 접근해야 하는 상황을 말하며, 이로 인해 훨씬 더 긴 지연 시간(latency)이 발생한다. 캐시 미스는 명령어 읽기 미스, 데이터 읽기 미스, 그리고 데이터 쓰기 미스의 세 가지 종류가 있다.[32]
캐시 성능 측정은 메모리 성능과 프로세서 성능 간의 속도 차이가 커지면서 중요해졌다. 캐시는 이러한 속도 차이를 줄이기 위해 도입되었다. 따라서 캐시가 프로세서와 메모리 간의 속도 차이를 얼마나 잘 메우는지 아는 것이 중요하며, 특히 고성능 시스템에서 더욱 중요하며, 캐시 적중률과 캐시 미스율은 이러한 성능을 결정하는 데 중요한 역할을 한다. 캐시 성능을 개선하기 위해 미스율 감소는 다른 단계들과 함께 필요한 단계 중 하나이다. 캐시에 대한 접근 시간을 줄이는 것 또한 성능을 향상시키고 최적화에 도움이 된다.[32]
6. 2. CPU 스톨
캐시 미스로 인해 CPU가 데이터를 기다리는 동안 작업을 다 써버리는 현상을 스톨이라고 한다. CPU가 메인 메모리에 비해 더 빨라짐에 따라 캐시 미스에 의한 스톨은 더 많은 잠재적 계산을 대체한다. 최신 CPU는 메인 메모리에서 단일 캐시 라인을 가져오는 데 걸리는 시간 안에 수백 개의 명령을 실행할 수 있다.[71]이 시간 동안 CPU를 계속 사용하기 위해 다양한 기술이 사용되어 왔으며, 여기에는 캐시 미스 데이터를 기다리는 명령 뒤에 독립적인 명령을 실행하려는 CPU의 비순차적 실행이 포함된다. 많은 프로세서에서 사용되는 또 다른 기술은 동시 멀티스레딩(SMT)으로, 첫 번째 스레드가 필요한 CPU 리소스를 사용할 수 있을 때까지 기다리는 동안 다른 스레드가 CPU 코어를 사용할 수 있도록 한다.
예를 들어 SGEMV (단정밀 부동소수점의 행렬-벡터 곱 연산)을 생각해 보자. 2.0 GHz로 동작하는 Haswell CPU의 싱글 코어는 피크 시 128GB/s의 데이터 접근을 요구한다.[71] (8 FMA/명령 * 0.5 [CPI=cycle/inst.][72] * 2.0G [Hz=cycle/sec] * 4 [Byte/FP32]) . 한편, 프로세서-메인 메모리 간의 지연 시간은 수백 사이클이며, 병렬 로드를 수행하더라도 최대 5GB/s밖에 데이터를 읽어낼 수 없다.[73] 즉, 메모리 병목 현상으로 인해 CPU 성능의 5% 이하밖에 끌어낼 수 없다.[74] 만약 행렬을 캐시에 모두 담을 수 있다면, 지연 시간이 더 작은 캐시 메모리에서 데이터를 공급하여 더 높은 데이터 대역폭을 확보할 수 있다.
6. 3. 연관성 (Associativity)
배치 정책은 주 메모리의 특정 항목 사본이 캐시 어디에 위치할지를 결정한다. 배치 정책에 따라 다음과 같이 분류할 수 있다.
- 완전 연관 (Fully Associative): 캐시의 임의 항목을 선택하여 사본을 보관할 수 있다.
- 직접 매핑 (Direct Mapped): 주 메모리의 각 항목이 캐시의 단 하나의 위치에만 매핑될 수 있다.
- N-웨이 집합 연관 (N-way Set Associative): 주 메모리의 각 항목이 캐시의 N개 위치 중 하나에 매핑될 수 있다. 예를 들어, AMD 애슬론의 레벨-1 데이터 캐시는 2-웨이 집합 연관 방식으로, 주 메모리의 특정 위치가 레벨-1 데이터 캐시의 두 위치 중 하나에 캐싱될 수 있다.[11]
적절한 연관성 값을 선택하려면 트레이드 오프가 필요하다. 배치 정책이 메모리 위치를 매핑할 수 있는 위치가 많을수록 해당 위치가 캐시에 있는지 확인하기 위해 더 많은 캐시 항목을 검색해야 한다. 이는 더 많은 전력, 칩 영역, 시간을 소모한다. 반면, 연관성이 높을수록 충돌 미스가 줄어들어 CPU가 느린 주 메모리에서 데이터를 읽는 데 낭비하는 시간이 줄어든다.
일반적으로 연관성을 두 배로 늘리면 (예: 직접 매핑 → 2-웨이, 2-웨이 → 4-웨이) 캐시 크기를 두 배로 늘리는 것과 거의 동일한 히트율 상승 효과를 얻을 수 있다. 그러나 연관성을 4 이상으로 증가시키는 것은 히트율을 크게 향상시키지 않으며,[12] 다른 이유 (가상 에일리어싱 참조)로 수행된다.[12] 일부 CPU는 저전력 상태에서 캐시 연관성을 동적으로 줄여 전력을 절약한다.[13]
캐시 연관성은 단순하지만 상황이 좋지 않은 것부터 복잡하지만 상황이 좋은 순서로 다음과 같이 나열할 수 있다.
- 직접 매핑 캐시: 최상의 경우 시간은 좋지만 최악의 경우 예측 불가능하다.
- 2-웨이 집합 연관 캐시
- 2-웨이 스큐드 연관 캐시[14]
- 4-웨이 집합 연관 캐시
- 8-웨이 집합 연관 캐시 (후기 구현에서 일반적인 선택)
- 12-웨이 집합 연관 캐시 (8-웨이와 유사)
- 완전 연관 캐시: 최상의 미스율을 보이지만 소수의 항목에 대해서만 실용적이다.
캐시 메모리는 데이터를 라인(블록) 단위로 관리한다. (예: Intel Pentium 4의 8KB L1 캐시는 64바이트 라인 크기를 가짐). 데이터 접근 요구 시 해당 데이터가 캐시에 존재하는지, 어떤 라인에 있는지 등을 빠르게 (대부분 1사이클 처리량) 검색해야 한다. 이를 위해 데이터 저장 주소 일부 (라인 단위 주소의 하위 비트, 엔트리 주소)를 이용하여 저장 위치를 한정하여 검색 속도를 높인다.
각 라인에는 라인 단위 주소의 상위 비트 (프레임 주소)를 저장하고, 캐시 검색 시 검색 주소의 프레임 주소부와 캐시 내 저장된 검색 엔트리 주소 위치 (엔트리 주소부를 디코딩하여 라인 선택)에 대응하는 프레임 주소를 비교하여 캐시 히트를 검출한다. 이 프레임 주소 저장 버퍼가 태그이다. 여러 세트의 태그를 가지면 동일 엔트리 주소에서도 여러 데이터 저장이 가능하다. 이 태그 세트 수 (웨이)를 연관도라고 하며, 데이터 저장 구조의 차이는 연관도의 차이로 나타난다.
- 다이렉트 맵 방식 (Direct Mapped): 1개 태그로 구성 (연관도 1)된 데이터 저장 구조이다. 주소에 의해 배치가 유일하게 결정되므로 태그 구조가 단순하다. 하지만 동일 엔트리에 다른 프레임 주소가 전송되면 반드시 라인 교체가 발생한다. 라인 교체가 빈번하여 처리량이 떨어지는 캐시 슬래싱이 발생하기 쉽고 히트율이 높지 않다.
- 세트 연관 방식 (Set Associative): 복수 태그로 구성 (연관도 2 이상)된 데이터 저장 구조이다. 동일 엔트리에 다른 프레임 주소 데이터를 복수 저장할 수 있다. 연관도가 높을수록 캐시 히트율이 상승하지만 제조가 어렵기 때문에 시스템에 따라 균형 잡힌 구현이 필요하다. n개 태그로 구성된 경우 n-웨이 세트 연관 방식이라고 한다. 최근에는 CAM (연관 메모리)이 태그로 사용되어 32 등 매우 높은 연관도 구현이 가능해졌다. 다이렉트 맵 방식과 풀 연관 방식은 이 방식의 특수한 경우이다.
- 풀 연관 방식 (Fully Associative): 엔트리 주소에 의한 배분 없이 모든 라인이 검색 대상이 되는 구조이다. 연관도는 라인 수만큼 된다. 캐시 슬래싱이 일어나기 어렵고 히트율이 가장 우수하지만 구현 비용 및 복잡성 때문에 일반적으로 사용되지 않는다.
7. 소프트웨어에 대한 영향
CPU 캐시의 존재는 일관성을 명시적으로 제어해야 하는 경우를 제외하고는 소프트웨어의 동작에 대해 투명하다. 한편, 성능 측면에서는 캐시 메모리의 존재나 사양을 의식함으로써 향상을 도모할 수 있다.
- 솔라리스의 슬랩 할당은 특정 구조체 멤버에 접근이 집중되는 경향을 이용하여 캐시 라인 내에서 자주 접근되는 위치를 분산시켰다.[77]
- 자주 갱신되는 데이터와 그렇지 않은 데이터를 분리하여 캐시 라인 상에 배치하면 쓰기 반환이 필요한 캐시 라인 수를 줄여 효율을 높일 수 있다.[78][79]
7. 1. 슬랩 할당
솔라리스 2.4 커널에서 채택된 슬랩 할당영어은 구조체의 특정 멤버에 액세스가 집중되는 경향을 이용한다. 각 슬랩에서 객체 영역의 선두에 다른 슬랩 선두로부터의 오프셋을 부여해 캐시 라인 내에서 빈번하게 액세스되는 위치를 분산시킨다.[77] 당시 썬이 판매하던 제품에서는 메모리 인터리빙과 함께 캐시 라인 내를 더욱 여러 개의 메모리 버스로 분할하여 할당했다. 이 때문에 캐시 라인 내에서 액세스가 빈번한 위치가 특정 위치에 집중되면 캐시 라인뿐만 아니라 메모리 버스의 부하도 분산되지 않는다는 문제가 발생했고, 슬랩 할당은 그 해결책으로 사용되었다.7. 2. 데이터 배치
동일한 캐시 라인 내에 자주 갱신되는 데이터와 거의 갱신되지 않는 데이터가 함께 있으면, 시스템 전체적으로 메인 메모리로 쓰기 반환을 해야 하는 캐시 라인 수가 늘어난다. 따라서 이 둘을 캐시 라인 상에서 분리하여 데이터를 배치하면 쓰기 반환이 필요한 캐시 라인의 수를 줄여 효율을 높일 수 있다.[78][79] 리눅스 커널이나 FreeBSD 등에서는 거의 갱신되지 않는 데이터를 ELF의 특정 섹션에 정의하여 이러한 데이터만 모은 다음 캐시 라인 경계에 정렬시키고 있다.참조
[1]
웹사이트
How The Cache Memory Works
https://hardwaresecr[...]
2007-09-12
[2]
논문
Survey of CPU Cache-Based Side-Channel Attacks: Systematic Analysis, Security Models, and Countermeasures
2021-06-10
[3]
웹사이트
Atlas 2 at Cambridge Mathematical Laboratory (and Aldermaston and CAD Centre)
http://www.chilton-c[...]
2012-11-01
[4]
웹사이트
IBM System/360 Model 85 Functional Characteristics
http://www.bitsavers[...]
IBM
1968-06-01
[5]
논문
Structural aspects of the System/360 Model 85 - Part II The cache
https://www.andrew.c[...]
1968-03-01
[6]
논문
Cache Memories
http://home.eng.iast[...]
1982-09-01
[7]
간행물
Altering Computer Architecture is Way to Raise Throughput, Suggest IBM Researchers
1976-12-01
[8]
웹사이트
IBM z13 and IBM z13s Technical Introduction
https://www.redbooks[...]
IBM
2016-03-01
[9]
보도자료
Product Fact Sheet: Accelerating 5G Network Infrastructure, from the Core to the Edge
https://www.intel.co[...]
Intel Corporation
2024-04-18
[10]
웹사이트
Intel Launches Atom P5900: A 10nm Atom for Radio Access Networks
https://www.anandtec[...]
2020-04-12
[11]
웹사이트
Cache design
https://cseweb.ucsd.[...]
2010-12-02
[12]
학회
Phased set associative cache design for reduced power consumption
https://ieeexplore.i[...]
2009
[13]
웹사이트
Power Management of the Third Generation Intel Core Micro Architecture formerly codenamed Ivy Bridge
https://web.archive.[...]
2020-07-29
[14]
논문
A Case for Two-Way Skewed-Associative Caches
1993
[15]
웹사이트
Lecture 3: Advanced Caching Techniques
https://web.archive.[...]
2012-09-07
[16]
웹사이트
Micro-Architecture
https://www.irisa.fr[...]
[17]
논문
Two fast and high-associativity cache schemes
1997-09-01
[18]
웹사이트
ARM Cortex-R Series Programmer's Guide
https://developer.ar[...]
2014
[19]
웹사이트
Way-predicting cache memory
https://patents.goog[...]
[20]
웹사이트
Reconfigurable multi-way associative cache memory
https://patents.goog[...]
1994-11-22
[21]
웹사이트
US Patent Application for DYNAMIC CACHE REPLACEMENT WAY SELECTION BASED ON ADDRESS TAG BITS Patent Application (Application #20160350229 issued December 1, 2016) – Justia Patents Search
https://patents.just[...]
[22]
웹사이트
Choosing an Error Protection Scheme for a Microprocessor's L1 Data Cache
https://people.ee.du[...]
[23]
서적
Computer Architecture: A Quantitative Approach
https://books.google[...]
Elsevier
[24]
서적
Computer Organization and Design: The Hardware/Software Interface
https://books.google[...]
Morgan Kaufmann
[25]
웹사이트
Cache Basics
http://www.ccs.neu.e[...]
[26]
웹사이트
Concerning Cache
http://www.cs.washin[...]
[27]
서적
Memory Systems and Pipelined Processors
https://books.google[...]
Jones & Bartlett Learning
1996
[28]
학회
Experience using a time sharing multiprogramming system with dynamic address relocation hardware
[29]
학회
A New Perspective for Efficient Virtual-Cache Coherence
2013
[30]
잡지
Understanding Caching
http://www.linuxjour[...]
2004
[31]
논문
The TLB Slice - A Low-Cost High-Speed Address Translation Mechanism
[32]
웹사이트
Advanced Operating Systems Caches and TLBs (263-3800-00L)
https://web.archive.[...]
2009-03-03
[33]
학회
Gaining insights into multicore cache partitioning: Bridging the gap between simulation and real systems
2008
[34]
웹사이트
Letter to Jiang Lin
http://web.cse.ohio-[...]
[35]
학회
Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers
1990-05-01
[36]
웹사이트
Products (Formerly Crystal Well)
http://ark.intel.com[...]
Intel
2013-09-15
[37]
웹사이트
Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
http://www.anandtech[...]
AnandTech
2013-09-16
[38]
웹사이트
The Intel Skylake Mobile and Desktop Launch, with Architecture Analysis
http://www.anandtech[...]
AnandTech
2015-09-02
[39]
웹사이트
The Pentium 4's Cache – Intel Pentium 4 1.4 GHz & 1.5 GHz
http://www.anandtech[...]
AnandTech
2000-11-20
[40]
웹사이트
AMD's Bulldozer Microarchitecture – Memory Subsystem Continued
http://www.realworld[...]
2010-08-26
[41]
웹사이트
Intel's Sandy Bridge Microarchitecture – Instruction Decode and uop Cache
http://www.realworld[...]
2010-09-25
[42]
논문
Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA
http://cecs.uci.edu/[...]
Association for Computing Machinery
2001-08
[43]
웹사이트
The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers
http://www.agner.org[...]
2014-02-19
[44]
웹사이트
Intel's Haswell Architecture Analyzed
http://www.anandtech[...]
AnandTech
2012-10-05
[45]
웹사이트
AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
http://www.anandtech[...]
AnandTech
2016-08-18
[46]
웹사이트
Trace Cache
https://www.cs.cmu.e[...]
2003-10
[47]
웹사이트
How does the BTIC (branch target instruction cache) work?
https://community.ar[...]
2015-05-28
[48]
웹사이트
Intel Smart Cache: Demo
http://www.intel.com[...]
Intel
2012-01-26
[49]
웹사이트
Inside Intel Core Microarchitecture and Smart Memory Access
http://software.inte[...]
Intel
2012-01-26
[50]
웹사이트
Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
http://www.anandtech[...]
AnandTech
2014-02-25
[51]
웹사이트
Software Techniques for Shared-Cache Multi-Core Systems
https://software.int[...]
Intel
2012-03-08
[52]
웹사이트
2nd Generation Intel Core Processor Family: Intel Core i7, i5 and i3
http://www.hotchips.[...]
2013-07-28
[53]
논문
A Simulation Based Study of TLB Performance
[54]
웹사이트
Explanation of the L1 and L2 Cache
http://www.amecomput[...]
2014-06-09
[55]
논문
Performance Evaluation of Exclusive Cache Hierarchies
http://mercury.pr.er[...]
2004-03-10
[56]
웹사이트
Achieving Non-Inclusive Cache Performance with Inclusive Caches
http://www.jaleels.o[...]
2010-09-27
[57]
웹사이트
AMD K8
http://www.sandpile.[...]
2007-06-02
[58]
웹사이트
Cortex-R4 and Cortex-R4F Technical Reference Manual
http://infocenter.ar[...]
arm.com
2013-09-28
[59]
웹사이트
L210 Cache Controller Technical Reference Manual
http://infocenter.ar[...]
arm.com
2013-09-28
[60]
논문
The processor-memory bottleneck: problems and solutions
https://epic.hpi.uni[...]
1999
[61]
서적
GE-645 System Manual
http://bitsavers.org[...]
General Electric
1968-01
[62]
서적
IBM System/360 Model 67 Functional Characteristics
http://www.bitsavers[...]
IBM
1972-02
[63]
논문
Parallel operation in the control data 6600
https://cs.uwaterloo[...]
1964-10
[64]
서적
IBM System/360 Model 85 Functional Characteristics
http://www.bitsavers[...]
IBM
1968-06
[65]
간행물
The 486 CPU: ON A High-Performance Flight Vector
Intel Corporation
1990-11
[66]
간행물
An Overview of High-performance Hardware Design Using the 486 CPU
Intel Corporation
1990-11
[67]
웹사이트
Intel Xeon Processor E7 Family
http://ark.intel.com[...]
Intel
2013-10-10
[68]
뉴스
Chip Design Thwarts Sneak Attack on Data
https://spectrum.iee[...]
2009-11
[69]
논문
A novel cache architecture with enhanced performance and security
http://palms.princet[...]
2008-11-08
[70]
웹사이트
CACTI
https://www.hpl.hp.c[...]
2023-01-29
[71]
논문
What You Must Know about Memory, Caches, and Shared Memory
https://www.eidos.ic[...]
東京大学
2016
[72]
웹사이트
Intel Intrinsics Guide
https://www.intel.co[...]
2022-04-03
[73]
논문
What You Must Know about Memory, Caches, and Shared Memory
https://www.eidos.ic[...]
東京大学
2016
[74]
논문
What You Must Know about Memory, Caches, and Shared Memory
https://www.eidos.ic[...]
東京大学
2016
[75]
논문
What You Must Know about Memory, Caches, and Shared Memory
https://www.eidos.ic[...]
東京大学
2018
[76]
논문
What You Must Know about Memory, Caches, and Shared Memory
https://www.eidos.ic[...]
東京大学
2018
[77]
학회발표
The Slab Allocator: An Object-Caching Kernel
https://www.usenix.o[...]
USENIX
1994-06-06
[78]
웹사이트
arch/x86/kernel/vmlinux.lds.S at master
https://github.com/t[...]
2024-05-26
[79]
웹사이트
sys/conf/ldscript.amd64 at main
https://github.com/f[...]
2024-05-26
[80]
웹인용
How The Cache Memory Works
http://www.hardwares[...]
2007-09-12
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com